AIセルフセキュリティ
インテリジェントワールドを目指す
ビッグデータの蓄積、計算能力の劇的な改善、機械学習(ML)による手法の継続的な革新により、画像認識、音声認識、自然言語処理などの人工知能(AI)テクノロジーが至る所に普及するようになりました。一方、AIはコンピュータのセキュリティに多大な影響を与えます。AIはマルウェアやネットワーク攻撃の検出などの防御システムの構築に使用できる一方で、より効果的な攻撃を仕掛けるためにAIが悪用される可能性があります。いくつかのシナリオでは、AIシステムのセキュリティは生死にかかわる問題です。したがって、外部からの干渉を受けない堅牢なAIシステムを構築することが不可欠です。AIはセキュリティを向上させることができる一方で、その逆もまた然りです。
この文書の主な目的は、AIモデルとデータの整合性と機密性を保護し、攻撃者が推論結果を変更したり、データを盗んだりすることを防ぐという観点からAIのセキュリティについて調査することです。
従来のシステムにおけるセキュリティの脆弱性とは異なり、MLシステムにおけるセキュリティの脆弱性の根本的な原因は、AIシステムの説明可能性の欠如にあります。この説明可能性の欠如は、回避、ポイズニング、バックドア攻撃などの敵対的な機械学習法によって悪用される可能性のある侵入口を残します。このような攻撃は非常に効果的であり、異なるMLモデル間で強力な伝染可能性を持つため、ディープニューラルネットワーク(Deep Neural Network、DNN)ベースのAIアプリケーションに深刻なセキュリティ上の脅威をもたらします。たとえば、攻撃者はトレーニング段階で悪意のあるデータを挿入してAIモデルの推論に影響を与えたり、推論段階で入力サンプルに小さな変化を加えて推論結果を変更したりできます。攻撃者は、モデルにバックドアを埋め込み、標的型攻撃を開始したり、クエリ結果からモデルパラメーターまたはトレーニングデータを抽出したりすることもあります。
新しいAIセキュリティの課題に取り組むために、この文書では以下のようにAIシステムを展開するための3層の防御を提案します。
- 攻撃の軽減:既知の攻撃に対する防御メカニズムを設計します。
- モデルのセキュリティ:モデル検証などのさまざまなメカニズムにより、モデルの堅牢性を強化します。
- アーキテクチャのセキュリティ:複数のセキュリティメカニズムを備えた安全なアーキテクチャを構築し、ビジネス上のセキュリティを確保します。
AIセキュリティの5つの課題
AIはより良い、よりスマートな世界を構築する大きな可能性を秘めていますが、同時に深刻なセキュリティリスクにも直面しています。AIアルゴリズムの初期開発ではセキュリティを考慮していなかったため、攻撃者は推論結果を誤判断へと導く方法を使用して、操作することができます。医療、運輸、監視などの重要な分野では、セキュリティリスクは壊滅的な影響を及ぼす可能性があります。AIシステムへの攻撃が成功すると、財産を失ったり、個人の安全が脅かされたりする可能性があります。
AIセキュリティリスクは、理論的な分析だけでなく、AIの展開にも存在します。たとえば、攻撃者はAIベースの検出ツールをバイパスするファイルを作成したり、スマートホームの音声制御コマンドにノイズを追加して悪意のあるアプリケーションを起動したりできます。攻撃者は、端末から返されたデータを改ざんしたり、故意にチャットロボットと悪意のある対話を行ったりして、バックエンドのAIシステムで予測エラーを引き起こすこともできます。自動運転車が誤った判断をするような小さなステッカーを道路標識や車両に貼ることさえ可能です。
このようなAIセキュリティリスクを軽減するには、AIシステム設計において、以下の5つのセキュリティ上の課題を克服する必要があります。
- ソフトウェアおよびハードウェアのセキュリティ:アプリケーション、モデル、プラットフォーム、およびチップのコードには、攻撃者が悪用できる脆弱性またはバックドアが含まれている場合があります。さらに、攻撃者はモデルにバックドアを埋め込み、高度な攻撃を仕掛けることがあります。AIモデルは説明できないため、バックドアを発見するのが困難です。
- データの整合性:攻撃者はトレーニング段階で悪意のあるデータを挿入してAIモデルの推論機能に影響を与えたり、推論段階で入力サンプルに小さな変化を加えて推論結果を変更したりできます。
- モデルの機密性:サービスプロバイダは通常、トレーニングモデルを公開せずにクエリサービスのみを提供することを望んでいます。ただし、攻撃者は多数のクエリを使用してクローンモデルを作成する可能性があります。
- モデルの堅牢性:トレーニングサンプルは通常、考えられるすべてのコーナーケースを網羅しているわけではないため、堅牢性が不十分です。したがって、モデルは敵対的なサンプルについて正しく推論できない可能性があります。
- データのプライバシー:ユーザーがトレーニングデータを提供するシナリオでは、攻撃者はトレーニングされたモデルに対して繰り返しクエリを実行することでユーザーの個人情報を取得できます。
AIセキュリティの多層防御
図3-1に示すように、サービスシナリオでAIシステムを展開するには、以下の3つの防御層が必要です。これは、攻撃の緩和、モデルのセキュリティ、およびアーキテクチャのセキュリティです。
図1-1 AIセキュリティの防御アーキテクチャ
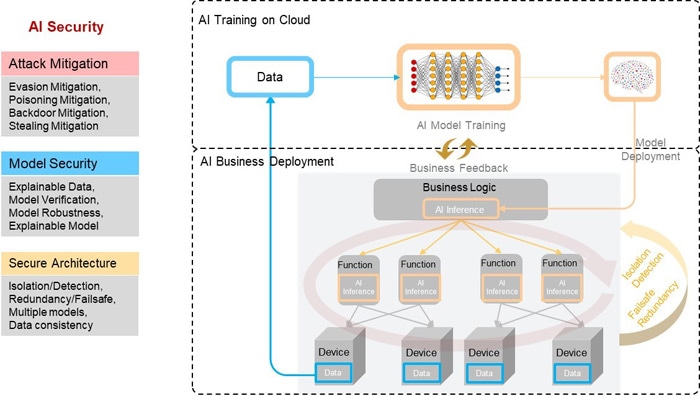
攻撃の軽減:既知の攻撃に対する防御メカニズムを設計します。典型的なAIセキュリティ攻撃には、回避攻撃、ポイズニング攻撃、バックドアおよびモデル抽出が含まれます。このような攻撃に対して、敵対的トレーニング、ネットワーク蒸留、敵対的検出、DNNモデル検証、データフィルタリング、アンサンブル分析、モデルプルーニング、PATEなど、多くの対策が文献で提案されています。
モデルのセキュリティ:敵対的MLは広範囲に存在します。回避攻撃、ポイズニング攻撃、および脆弱性とバックドアを利用するあらゆる種類の方法は正確であるだけでなく、強力な伝染可能性も備えているため、AIモデルによる誤判断のリスクが高くなります。したがって、既知の攻撃に対する防御に加えて、他の潜在的な攻撃によって引き起こされる損害を回避するために、AIモデル自体のセキュリティを強化する必要があります。潜在的な手法には、モデルの検出可能性、モデルの検証可能性、およびモデルの説明可能性が含まれます。
アーキテクチャのセキュリティ:AIシステムを開発する際には、その潜在的なセキュリティリスクに細心の注意を払う必要があります。予防メカニズムと制約条件を強化し、リスクを最小限に抑え、安全で信頼性の高い制御可能なAI開発を実施するようにします。AIモデルを適用する場合、特定のサービスの特性とアーキテクチャに基づいてAIモデルを使用する際のリスクを分析して決定し、分離、検出、フェールセーフ、冗長性を含むセキュリティメカニズムを使用して、堅牢なAIセキュリティアーキテクチャと展開ソリューションを設計する必要があります。